Come funziona il protocollo TCP
TCP (Transmission Control Protocol) è uno dei principali protocolli della suite protocollare TCP/IP ed è alla base del funzionamento di Internet. Fornisce la possibilità di trasferire dati in modo affidabile tra due dispositivi/host della rete, gestendo in modo per lo più trasparente funzioni come le connessioni, la conferma di ricezione dei pacchetti e il mantenimento del loro ordine, le ritrasmissioni, l’integrità dei dati, il controllo di flusso e della congestione.
Il protocollo è stato originariamente ideato negli anni 70 ed è rimasto in larga parte inviariato, anche se nel corso del tempo sono state introdotte diverse varianti per renderlo più efficiente. Anche se per alcuni scopi sono nati dei protocolli alternativi (come il recente QUIC, basato su UDP), TCP resta ampiamente dominante per molti scopi ed è quindi utile conoscerne il funzionamento.
Questo articolo è una panoramica tecnica del funzionamento interno di TCP, partendo dai concetti generali e approfondendo poi aspetti un po’ più avanzati. Questo articolo è pensato per utenti che non hanno già una preparazione avanzata di reti ma è necessario avere delle nozioni di base.
Funzionalità
TCP è un protocollo che offre la trasmissione di dati a livello di trasporto (il cosiddetto livello 4).
Nella pratica significa che i pacchetti TCP (più precisamente segmenti) vengono imbustati o incapsulati all’interno di pacchetti IP (livello 3 o di rete). Se lo scopo del livello di rete è implementare il routing e quindi trasportare un pacchetto dalla sorgente alla destinazione (basandosi sugli indirizzi IP), il livello trasporto si posiziona un livello “sopra” ed è in grado di distinguere i diversi flussi di dati delle diverse applicazioni.
TCP offre le seguenti funzionalità:
- la gestione delle connessioni: TCP è connection-oriented e richiede di stabilire una connessione bidirezionale tra i due host prima di poter iniziare la comunicazione. La connessione viene stabilita tramite una procedura chiamata three-way handshake (“stretta di mano a tre vie”), che vedremo in seguito;
- la consegna ordinata e affidabile: TCP è un protocollo affidabile perché garantisce che i dati inviati arriveranno prima o poi a destinazione. Garantisce inoltre che i pacchetti di dati vengano consegnati a destinazione nello stesso ordine in cui sono stati trasmessi. Per raggiungere questo obiettivo TCP mantiene un buffer di dati a finestra scorrevole su entrambe le estremità della connessione, consentendo di riordinare i pacchetti ricevuti nell’ordine errato, rilevare le perdite e confermare all’altro capo la ricezione di pacchetti senza errori;
- il rilevamento degli errori: ogni pacchetto TCP include una checksum che permette di verificare l’integrità dei dati ricevuti e quindi reagire correttamente alla corruzione dei dati che può avvenire durante la trasmissione in rete;
- il controllo di flusso: in TCP il ricevitore segnala continuamente all’altra estremità la quantità di dati che è ancora in grado di ricevere prima di riempire il buffer di dati. Questo permette di “chiedere” al trasmettitore di rallentare l’invio di pacchetti se il sistema non è in quel momento in grado di elaborarli;
- il controllo della congestione: TCP è in grado di rilevare quando la capacità massima della rete è stata raggiunta e adeguare di conseguenza la velocità di trasmissione. Questa è la parte più complessa di TCP e non a caso le varianti di TCP nate nel corso degli anni si distinguono in prevalenza per l’algoritmo di congestion control utilizzato.
Tutte queste funzionalità sono abilitate in modo predefinito senza che il codice delle applicazioni debba richiederle esplicitamente. Non è scontato, considerando che l’altro importante protocollo di livello trasporto, UDP (User Datagram Protocol), non fornisce nessuna di queste funzionalità, ad eccezione del rilevamento degli errori tramite checksum (opzionalmente).
Funzionamento di base
Come accennato, TCP si basa sulla suddivisione dei dati in piccoli segmenti. In principio un segmento potrebbe contenere qualsiasi quantità di byte ma nella pratica la lunghezza massima (MSS, Maximum Segment Size) viene limitata in modo da permettere l’inserimento del segmento TCP in un pacchetto IP senza costringere a frammentare il segmento in più parti. Di solito l’MSS è di poco inferiore ai 1500 byte (1,5 kB).
Oltre ai dati, ciascun segmento TCP include un header dalla dimensione minima di 20 byte. L’header contiene informazioni sul segmento che vengono poi utilizzate dall’altra estremità della connessione per sapere ad esempio quanti dati sono contenuti nel segmento o il numero di sequenza (utile ad esempio per poter ricostruire l’ordine dei segmenti).
Concettualmente le trasmissioni TCP si basano quindi sullo scambio di segmenti in entrambe le direzioni. Moltissime applicazioni che utilizzano TCP ne fanno un uso fortemente asincrono in termini di quantità di dati scambiati: ad esempio il download di un file prevede una richiesta al server da parte del client (in genere molto piccola e probabilmente contenuta in un singolo segmento) seguita da potenzialmente centinaia o migliaia di segmenti contenenti i dati effettivi. È importante tenere presente che TCP non ha il concetto di “file” o “messaggio”: i dati vengono spezzettati e inseriti in uno o più segmenti e sta poi al ricevitore ricostruire gli oggetti originali.
Ogni pacchetto di dati deve essere confermato tramite un ACK (da acknowledgment, conferma), cioè un nuovo segmento che il ricevitore invia al trasmettitore in cui viene specificato che i dati sono stati ricevuti correttamente.
Delayed ACKs e Nagle’s algorithm
Nella maggior parte delle implementazioni in realtà per questioni di efficienza gli ACK vengono ritardati di non più di qualche centinaia di millisecondi, in modo da ridurre il numero di segmenti sulla rete (delayed ACKs).
Sempre per questioni di efficienza i segmenti di dati molto piccoli vengono di solito raggrupppati in un unico segmento (Nagle’s algorithm).
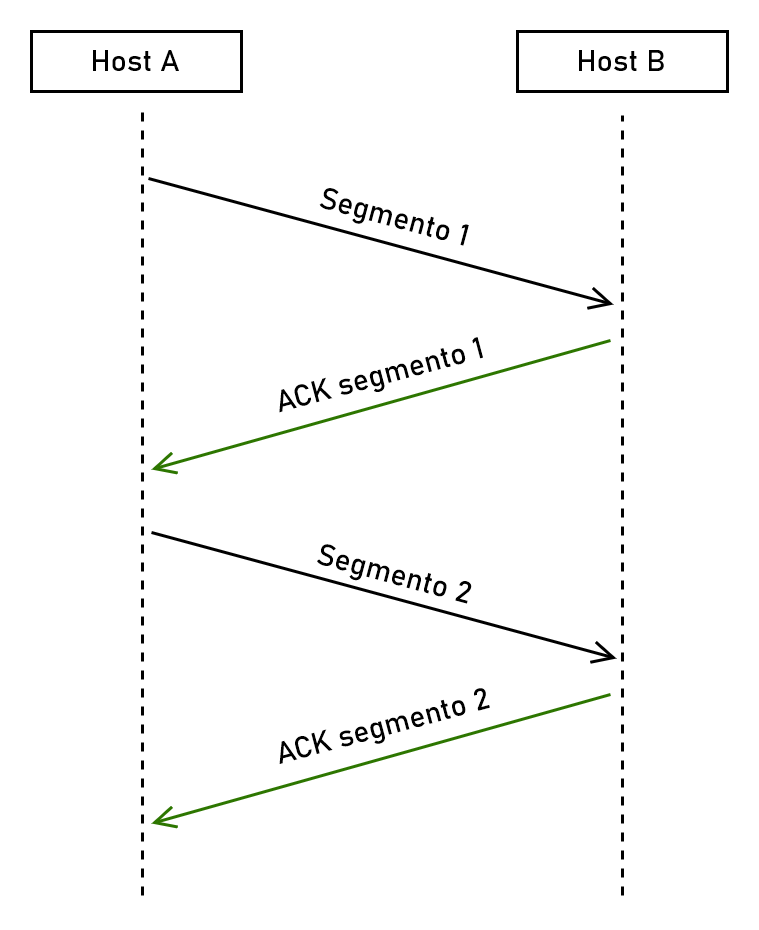
Trasmettitore e ricevitore
In TCP entrambi gli host di una connessione sono sia trasmettitore che ricevitore e l’uso dei termini dipende quindi dal contesto. In alcuni casi, come nell’esempio del download di un file, si tende a identificare come trasmettitore l’host che invia più dati tra i due.
L’header TCP

I campi più importanti sono i seguenti:
Source/destination port: le porte sorgente e destinazione che identificano quale applicazione sta inviando i dati e verso quale applicazione è destinato il segmento sull’altro host. Ad esempio, nel caso di una connessione TCP per trasportare traffico HTTP la porta di destinazione sarà 80 oppure 443, mentre quella sorgente sarà scelta casualmente. Il server risponderà utilizzando la porta casuale come porta di destinazione e 80 oppure 443 come porta sorgente. La porta è un valore numerico di 16 bit e può quindi variare tra 0 e 65535 (i primi 1024 valori sono riservati ai servizi più comuni).
Sequence number: è un contatore che tiene traccia del numero di byte trasmessi da un host. Ad esempio, se un segmento contiene 1000 byte il sequence number viene incrementato di 1000 dopo la trasmissione. È indipendente nelle due direzioni di trasmissioni, per cui entrambi gli host della connessione mantengono un proprio numero di sequenza e lo inseriscono nei propri pacchetti inviati. Trattandosi di un numero a 32 bit può arrivare ad oltre 4 miliardi (4 GB), dopodiché ricomincia da zero (wrap around).
Acknowledgment number: serve ad indicare all’altro capo della trasmissione che i dati precedenti al numero di sequenza indicato in questo campo sono stati ricevuti correttamente. Ad esempio se il valore è 5000 significa che i byte da 0 a 4999 sono stati ricevuti e che il ricevitore si aspetta ora il byte 5000 (che potrebbe essere già stato inviato ma non ancora arrivato a destinazione). Si tratta quindi di un meccanismo di conferma cumulativo.
Flags: sono una sequenza di bit di controllo. I più importanti sono ACK (se impostato a 1 indica che il campo Acknowledgment number ha un significato e va preso in considerazione), SYN, FIN e RST (che vedremo meglio in seguito).
Window size: specifica la dimensione della finestra di ricezione per il controllo di flusso. Vedremo meglio il significato di questo parametro nel capitolo dedicato.
Checksum: un codice che permette di rilevare se i dati si sono corrotti in fase di trasferimento. Il calcolo della checksum in alcuni casi può essere dispendioso e viene quindi spesso implementato in hardware (checksum offloading).
Options: questa sezione è opzionale e permette di estendere l’header TCP con funzionalità aggiuntive. Alcuni esempi di opzioni normalmente utilizzate sono:
- Maximum segment size (MSS): permette di comunicare all’altro host la quantità massima di dati che è in grado di ricevere in un singolo segmento TCP;
- Selective acknowledgments (SACK): permette di variare il sistema di ACK da cumulativo a selettivo. In questo modo il ricevitore anziché confermare di aver ricevuto tutti i dati fino a un certo numero di sequenza può confermare più intervalli di dati (comunicando così implicitamente quali pacchetti non sono ancora stati ricevuti);
- Window scale: permette di moltiplicare il valore della Window size, che altrimenti potrebbe arrivare solo fino a 64 KB. In dettaglio, la window scale indica il numero di shift bitwise da applicare alla dimensione della finestra, il cui valore effettivo può quindi essere calcolato con la formula $\operatorname{WindowSize} \cdot 2^{\operatorname{WindowScale}}$ .
L’handshake a tre vie
Prima di iniziare a scambiarsi dati due host devono stabilire una connessione. Questa fase è necessaria perché gli host devono sincronizzare i rispettivi numeri di sequenza iniziali (il numero di sequenza non inizia infatti da zero ma da un numero casuale, per prevenire attacchi di hijacking della connessione).
La sincronizzazione avviene tramite una procedura di handshake a tre vie (three-way handshake), che sfrutta alcuni dei flag visti nella sezione precedente.
In particolare un handshake TCP avviene con lo scambio di tre segmenti:
l’host che vuole aprire la connessione (A) invia un segmento TCP con il flag SYN (synchronization) abilitato e un numero di sequenza iniziale scelto casualmente (
X). Il segmento è in genere vuoto, non contiene dati;l’host destinatario (B) risponde a sua volta con un segmento TCP con il flag SYN e relativo numero di sequenza iniziale casuale (
Y). Imposta anche il flag ACK e nel campo Acknowledgment number inserisce il numero di sequenza di A incrementato di 1 (X+1), confermando quindi ad A la ricezione del segmento iniziale;l’host A riceve il segmento con il numero di sequenza di B (
Y) e risponde a sua volta con un segmento ACK e il valoreY+1nel campo Acknowledgment number. In questo segmento può iniziare ad inserire i dati che vuole trasmettere.
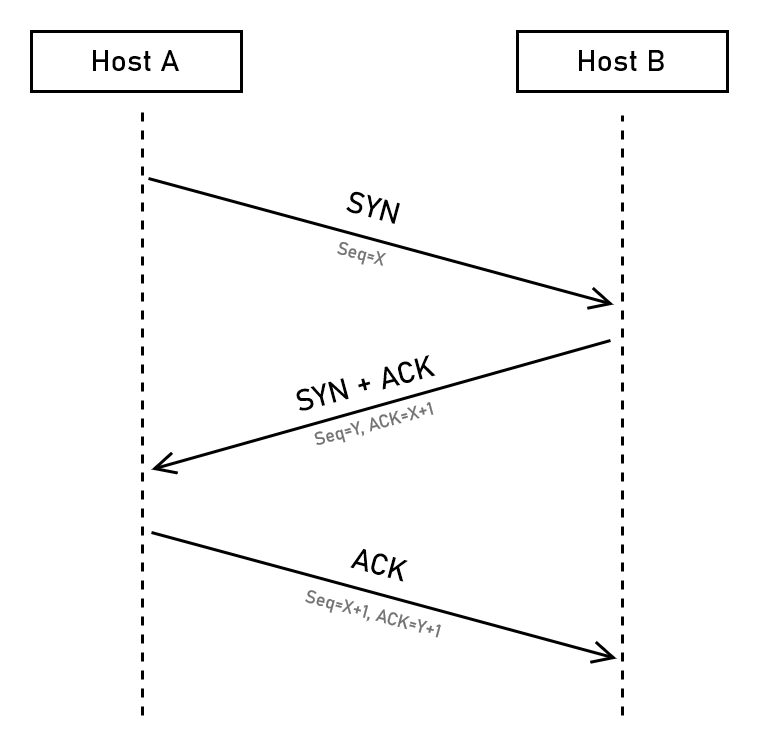
La procedura potrebbe sembrare inutilmente complicata ma per capire perché è necessaria è utile vederla divisa in due parti, con ciascuno dei due host che invia un pacchetto di sincronizzazione e attende la relativa conferma. In altre parole: l’host A potrebbe inviare un segmento SYN a B e attendere un ACK, poi l’host B invierebbe un segmento SYN ad A attendendo un ACK di risposta. È facile vedere che unendo le due fasi si ottiene proprio l’handshake TCP.
La gestione delle connessioni TCP è in genere implementata dai sistemi operativi, che espongono delle apposite system call per instaurarne di nuove. In questo contesto si usa spesso il termine socket per indicare un canale di comunicazione che corrisponde poi a una connessione TCP (o ad altri protocolli). Per fare un esempio, il breve codice Python riportato in seguito crea un socket TCP (= socket.SOCK_STREAM) tramite il quale viene aperta una connessione e vengono inviati dei dati. In questo caso la porta destinazione corrisponde alla variabile PORT mentre quella sorgente viene scelta casualmente.
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((HOST, PORT))
s.sendall(b'Hello world')
È importante comprendere che una connessione TCP non esiste nella rete ma soltanto sui due host, proprio grazie al fatto che gli host tengono traccia dei socket aperti e quindi delle relative connessioni. Nell’eventualità che uno dei due host sparisca improvvisamente, il socket resterà aperto fino a quando l’altro host non si accorgerà che non sta ricevendo più risposte.
L’attacco SYN flood
Per via di come funziona l’handshake esiste la possibilità che un client non completi mai la procedura di handshake e lasci quindi il server in attesa dell’ACK “finale”. L’attacco SYN flood consiste nel generare una grande quantità di segmenti SYN con l’obiettivo di esaurire le risorse del server, che deve inizializzare la connessione, riservare una porta e allocare della memoria già prima che l’handshake sia completato.
L’attacco è uno dei più comuni e longevi nell’ambito delle reti ed esistono diversi metodi per mitigarlo.
TCP Fast Open
L’handshake TCP introduce un ritardo di un Round-Trip Time (RTT) all’inizio di ogni connessione prima che si possano trasferire i dati. Un RTT corrisponde al tempo per trasmettere un segmento dall’host A all’host B e tornare indietro. L’estensione TCP Fast Open (TFO) permette ai client di ottenere alla prima connessione TCP un codice, TFO cookie, che può essere usato le volte successive come metodo di “autenticazione” per velocizzare l’avvio della connessione. Trasmettendo infatti il TFO cookie il client potrà iniziare a trasmettere dati già nel primo segmento SYN, senza attendere il completamento dell’handshake.
La chiusura di una connessione TCP avviene in modo molto simile all’handshake di apertura, con l’uso del flag FIN al posto di SYN. In pratica si ha quindi l’invio di un FIN da parte dell’host che vuole chiudere la connessione, seguito in risposta da un FIN+ACK e poi di nuovo ACK. Esiste anche la possibilità di chiudere la connessione in modo più brusco semplicemente smettendo di inviare e ricevere dati e inviando un segmento con il flag RST (reset).
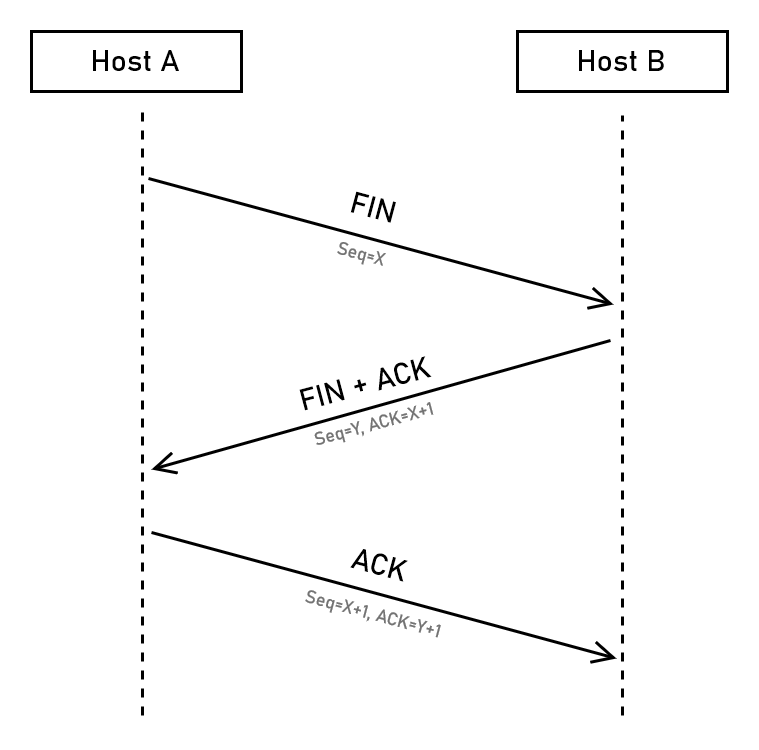
La gestione delle ritrasmissioni
I pacchetti di dati sulla rete possono andare persi per diversi motivi: i router potrebbero scartare pacchetti perché congestionati ma ci possono anche essere bug software o problemi hardware.
TCP è in grado di accorgersi della perdita di un pacchetto (e quindi ritrasmettere il pacchetto perso) principalmente tramite due metodi: l’uso di un timeout di ritrasmissione (RTO) e degli acknowledgment cumulativi duplicati (DupAck).
Il timeout di ritrasmissione
Per ogni segmento TCP inviato viene creato un timer che determina entro quanto tempo l’host si attende che il segmento venga confermato tramite un ACK.
Ovviamente il tempo minimo richiesto è dato da un Round-Trip Time (RTT), cioè il tempo richiesto perché il segmento arrivi a destinazione e l’ACK torni indietro. Semplificando leggermente, il valore del timeout (RTO) viene calcolato partendo dall’RTT e aggiungendo 4 volte la variazione dell’RTT, cioè $\operatorname{RTO} = \operatorname{RTT} + 4 \cdot \operatorname{RTTvar}$ .
Lo scopo è tenere conto del fatto che l’RTT non è sempre stabile e può variare nel tempo. Il moltiplicatore 4 è stato scelto empiricamente come un valore che sembrava adeguato per la maggior parte delle situazioni. Le implementazioni di TCP dei sistemi operativi possono stabilire anche un valore minimo di RTO, ad esempio in Linux è 200 ms mentre su Windows 300 ms.1
Quando il timeout scatta, il pacchetto di dati corrispondente viene dato per perso e viene ritrasmesso (identico). Il valore di RTO per il pacchetto ritrasmesso viene raddoppiato per evitare che il timeout scatti di nuovo (la rete potrebbe essere fortemente congestionata e l’ACK potrebbe non arrivare in tempo). TCP continua a ritrasmettere il pacchetto per un numero massimo di volte che dipende dalla configurazione del sistema operativo. Spesso il limite è di 15 ritrasmissioni, che si traduce in diversi minuti di tentativi.
Gli acknowledgment duplicati
La ritrasmissione dei pacchetti persi tramite timeout è un metodo che impedisce a TCP di reagire rapidamente alle perdite perché richiede potenzialmente anche centinaia di millisecondi.
Per questo esiste una strategia aggiuntiva basata sul rilevamento degli acknowledgment duplicati, che vengono inviati dal ricevitore quando riceve il segmento “sbagliato”.
Facciamo un esempio, aiutandoci con lo schema che trovate di seguito:
- l’host A trasmette 4 segmenti TCP a B, con numeri di sequenza che vanno da
1a4(in questo esempio usiamo i numeri di sequenza come “contatore”) - ✅ B riceve il segmento
1e invia l’ACK di risposta specificando che ora attende il segmento2 - ⚠️ il segmento
2viene perso, non arriverà mai a B - ❌ B riceve il segmento
3, ma si attendeva il segmento2. Invia quindi nuovamente un ACK specificando che si attende2 - ❌ B riceve il segmento
4, ma sta ancora attendendo il2! Invia un altro ACK identico al precedente - A riceve l’ACK per il segmento
1, non una volta ma tre volte. Può quindi concludere che qualcosa è andato storto e che probabilmente il segmento2è andato perso - A ritrasmette il segmento
2
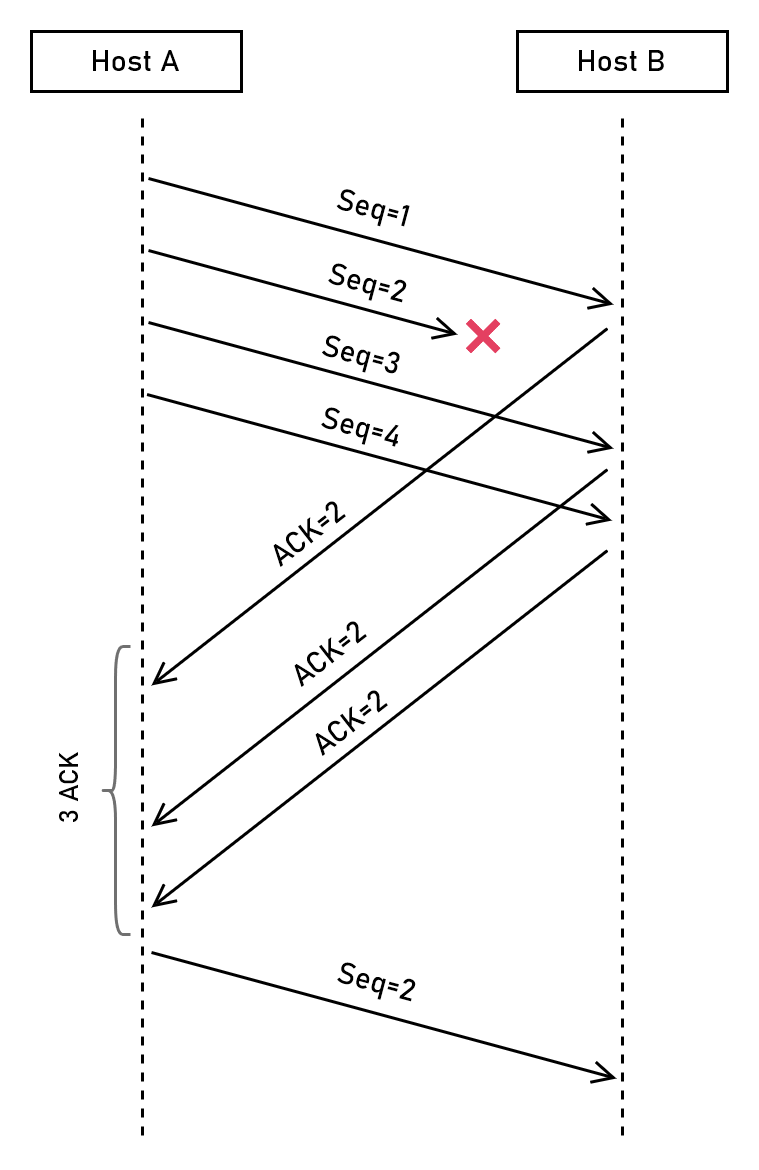
Gli acknowledgment duplicati (DupAck) possono quindi essere utilizzati per rilevare la perdita di pacchetti in modo più rapido rispetto al timeout di ritrasmissione. Come vedremo in seguito hanno anche un impatto molto più limitato negli algoritmi di controllo della congestione.
Il numero di DupAck che fa scattare una ritrasmissione è di solito 2 (oltre all’ACK originale, quindi 3 in totale come nell’esempio). Il valore è stato scelto come un compromesso per evitare che la consegna non ordinata di segmenti (che può capitare nel percorso di rete tra i due host) generi inutili ritrasmissioni.
Il controllo di flusso
Uno dei problemi principali dei protocolli di trasporto è regolare il flusso di dati in base alla capacità del destinatario di ricevere ed elaborare i pacchetti in ogni dato momento.
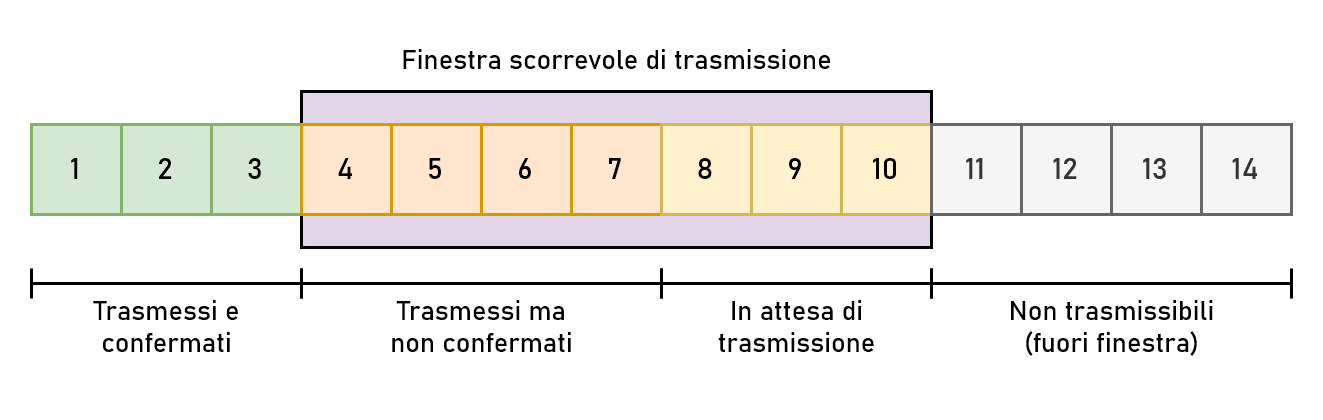
In TCP questo avviene tramite un sistema a finestra scorrevole. Il ricevitore comunica continuamente al trasmettitore quanto spazio ha ancora a disposizione nel proprio buffer, inserendo la quantità di byte nel campo Window size dell’header TCP. Il trasmettitore si assicura in qualsiasi momento che la quantità di byte trasmessi ma non ancora confermati (la finestra di trasmissione) sia inferiore o uguale al valore della finestra di ricezione del destinatario.
Per fare un esempio, se il ricevitore comunica che la propria finestra di ricezione è di 10.000 byte il trasmettitore ridimensionerà la propria finestra di trasmissione in modo che non sia più larga di 10.000 byte. Questo ha l’effetto di permettere al trasmettitore di inviare fino a 10.000 byte di dati prima di fermarsi in attesa di una conferma dal destinatario, in modo da non sovraccaricarlo.
La finestra è definita “scorrevole” perché non appena il trasmettitore riceve un ACK scorrerà la finestra in avanti, “sbloccando” l’invio di nuovi segmenti di dati.
Il controllo della congestione
Se la finestra di ricezione serve per regolare la velocità di invio in base alla capacità del ricevitore, TCP prevede anche l’uso di una finestra di congestione per regolare la velocità di trasferimento in base alla capacità della rete. La finestra di trasmissione effettiva è data quindi dal valore minimo tra le due finestre ed è quella che determina nella pratica la banda utilizzata da TCP.
Un grande problema non ancora completamente risolto è riuscire a regolare la finestra di congestione in modo che aderisca il più possibile alla velocità che la rete è in grado di sostenere. Il problema non è banale perché la capacità può variare nel tempo, per cui bisogna tenere conto sia di aumenti che riduzioni nel tempo. Non solo, sulla stessa rete ci possono essere molte connessioni TCP e queste devono riuscire a spartirsi la banda nel modo più equo possibile (si parla infatti spesso di fairness delle diverse versioni di TCP, anche tra loro).
Quando parliamo di algoritmi di controllo della congestione ci riferiamo proprio alle soluzioni a questo problema. Nel corso degli anni sono state elaborate diverse versioni e vedremo qui in dettaglio le tre più importanti, NewReno, CUBIC e BBR, con qualche accenno ad altre versioni storiche.
NewReno
NewReno è la versione classica di TCP, sviluppata negli anni 80 e tutt’oggi implementata sostanzialmente in tutti i sistemi operativi. Non è ormai più in uso se non in casi particolari, ma è una pietra miliare che ci permette di introdurre i principali concetti che riguardano il controllo della congestione (ripresi poi anche dagli altri algoritmi più recenti).
NewReno è un algoritmo che viene definito reattivo: funziona incrementando la finestra di congestione (e quindi la velocità di trasmissione) finché non si accorge che sta iniziando a generare perdite di pacchetti sulla rete. In altre parole per riuscire a capire qual è la capacità massima della rete genera di proposito della congestione sulla rete. La congestione porta i router intermedi della rete a scartare i pacchetti che non sono in grado di gestire e TCP utilizza queste perdite come segnale del fatto che il limite della rete è stato raggiunto. Reagisce poi di conseguenza riducendo la finestra di congestione (e quindi rallentando la trasmissione).
ECN e RED
Alcune recenti implementazioni degli algoritmi di congestione sfruttano una funzionalità chiamata Explicit Congestion Notification (ECN), che consente ai router di segnalare esplicitamente la presenza di congestione tramite degli appositi campi degli header IP e TCP. Gli algoritmi ricevono così un segnale aggiuntivo al quale possono reagire.
Un’altra tecnica usata è la Random Early Detection (RED): prevede che i router inizino a scartare pacchetti prima di aver riempito le code, in modo da evitare che si crei congestione, pur mantenendo invariato il funzionamento degli algoritmi.
Passando più in dettaglio al funzionamento dell’algoritmo, in assenza di congestione l’algoritmo funziona in due fasi:
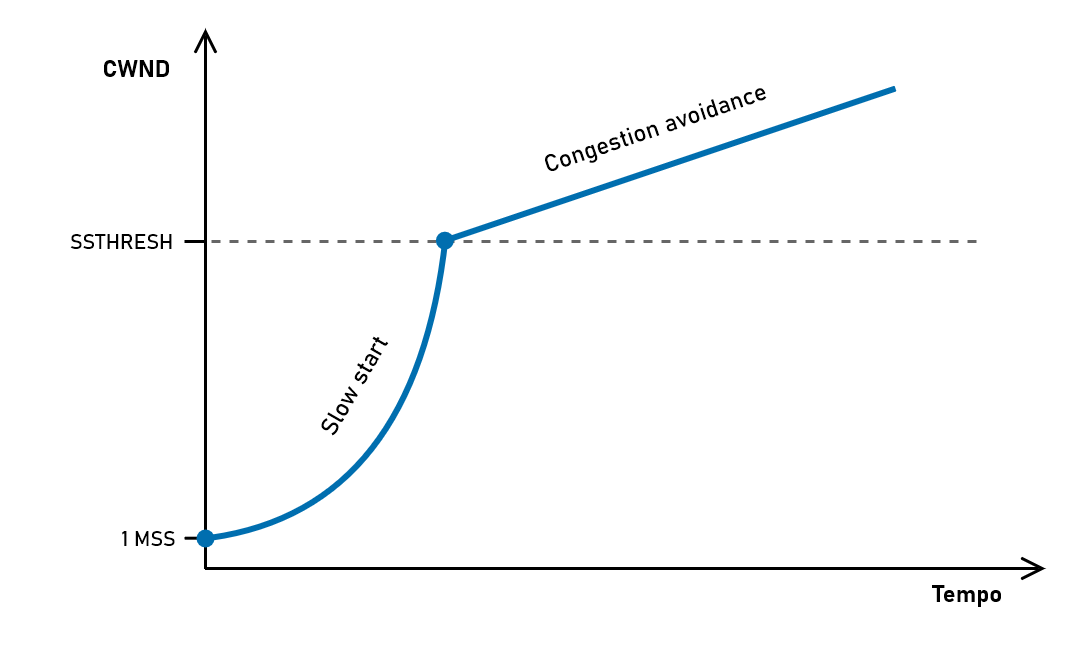
- Slow start → Questa è la fase iniziale della trasmissione e prevede una crescita molto rapida della finestra di congestione (che chiameremo CWND), in modo da aumentare rapidamente la velocità. La finestra è inizialmente di 1 MSS (1 segmento) e ad ogni ACK ricevuto viene incrementata di 1 MSS. La crescita della finestra in questa fase è esponenziale: la parola “slow” non si riferisce quindi alla crescita ma al fatto che la finestra parte da 1 MSS. Una volta raggiunta una certa soglia (SSTHRESH, slow start threshold) questa fase finisce e si passa in congestion avoidance.
- Congestion avoidance → In questa fase NewReno rallenta molto la crescita della finestra. Ad ogni ACK ricevuto la finestra CWND viene incrementata di $1 \cdot \operatorname{MSS} / \operatorname{CWND}$ , con il risultato di aumentare la finestra di 1 MSS ad ogni RTT (anziché ad ogni ACK come in slow start). La crescita in questa fase non è più esponenziale ma lineare.
In congestion avoidance la finestra di TCP continua a crescere ma a un certo punto raggiungerà il limite di banda della rete. I router inizieranno a scartare pacchetti e gli host osserveranno che i pacchetti vengono persi. Come visto in precedenza ci sono due modi con cui TCP può accorgersi delle perdite: il timeout (RTO) e gli acknowledgment duplicati.
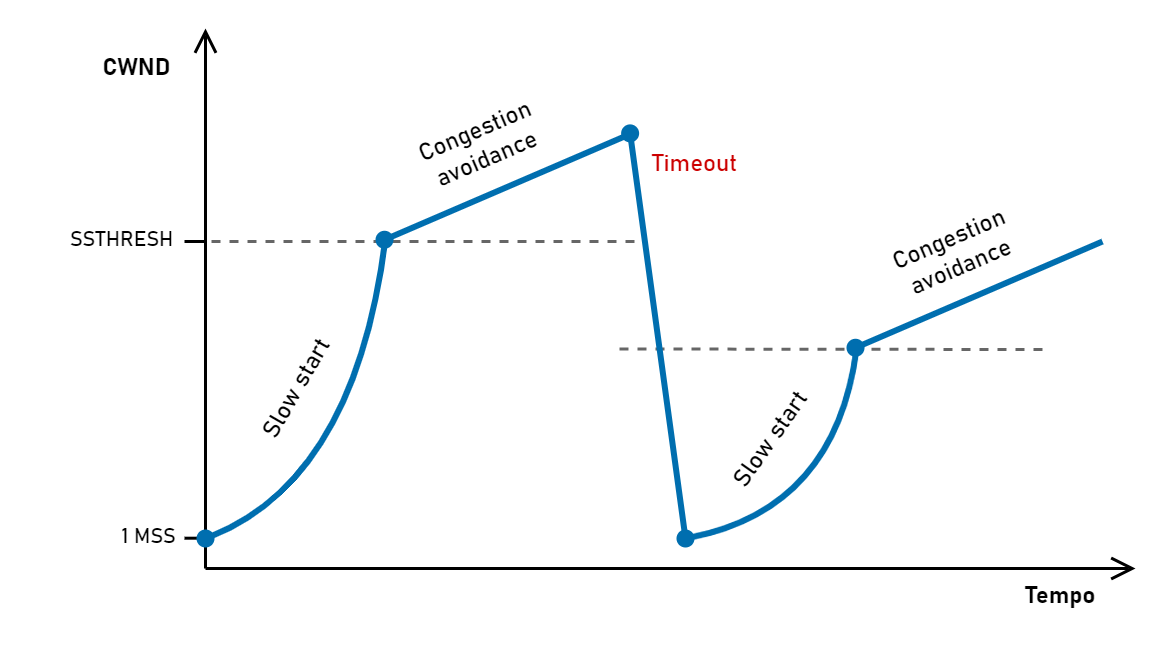
Il caso più semplice è il timeout: NewReno reagisce in modo drastico tornando in slow start. Riporta quindi la finestra a 1 MSS e ricomincia tutto da capo, abbassando però la soglia SSTHRESH alla metà della finestra raggiunta prima del timeout (entrando quindi in congestion avoidance quando si trova “a metà strada”).
NewReno “azzera” la finestra in caso di timeout perché la scadenza di un timeout è una situazione considerata grave, indice del fatto che i pacchetti non stanno più transitando in rete. Questo azzeramento comporta inevitabilmente una riduzione della velocità di trasmissione.
Una situazione più comune è che solo alcuni pacchetti vengano persi. In questo caso si possono sfruttare gli ACK duplicati: come visto in precedenza al terzo ACK per lo stesso numero di sequenza possiamo ritrasmettere il pacchetto perso. Questo comportamento fa parte di NewReno e viene chiamato fast retransmit.
Invece che tornare in slow start, dopo un fast retransmit TCP NewReno entra in fast recovery (“recupero rapido”). Semplificando un po’, non appena ricevuta conferma che il pacchetto ritrasmesso è stato ricevuto la connessione torna in congestion avoidance e ricomincia a crescere, partendo da metà della finestra raggiunta prima della perdita.
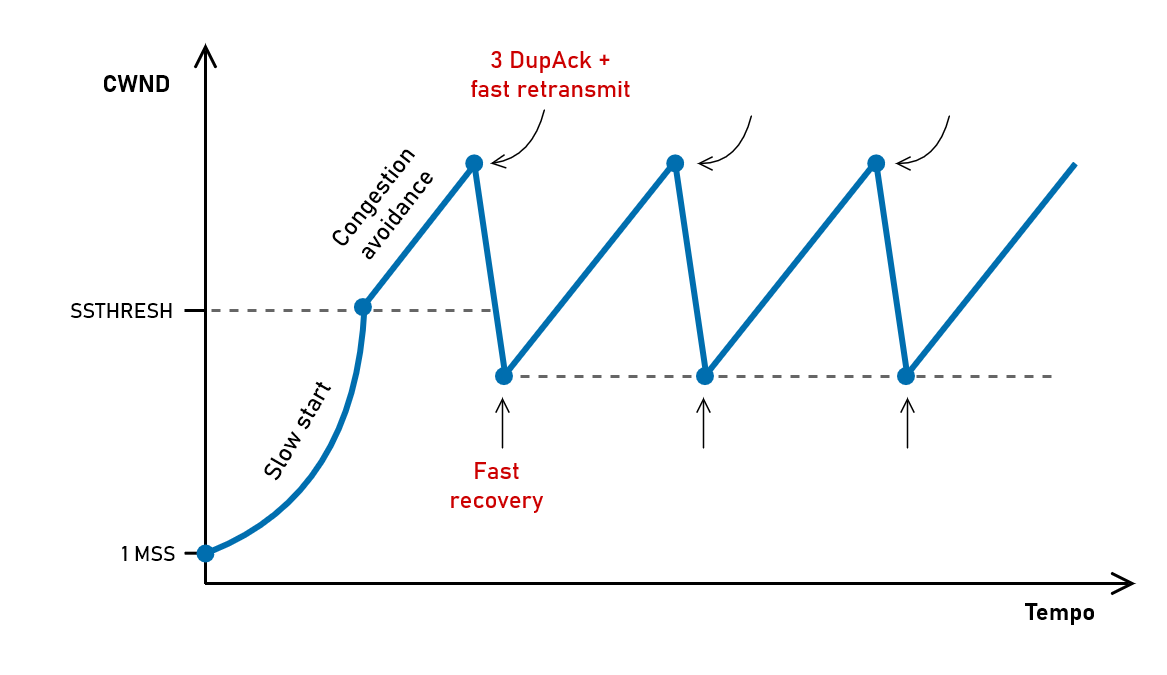
Una complicazione sorge dal fatto che se viene perso più di un pacchetto il trasmettitore dovrebbe assicurarsi che tutti i pacchetti persi siano stati recuperati e non soltanto il primo, prima di entrare in fast recovery. È questa la principale differenza tra NewReno e il suo predecessore, Reno.2 In questa fase ha un ruolo molto importante il supporto a SACK (Selective ACKnowledgments), che a differenza degli ACK cumulativi permette di sapere quali segmenti sono andati persi con precisione.
CUBIC
La strategia di controllo della congestione di NewReno viene definita Additive Increase Multiplicative Decrease (AIMD) perché la finestra cresce in modo additivo (linearmente con un aumento costante) in assenza di packet loss, mentre viene dimezzata in caso di perdite.
Questo approccio mostra tutti i suoi limiti nelle reti con molta banda: anche su una rete a 10 Gbps la perdita di un singolo pacchetto causa il dimezzamento della finestra di congestione e questo rende molto difficile mantenere una velocità di trasmissione così elevata in modo stabile. Un altro caso in cui NewReno funziona male è nelle reti con latenza e quindi RTT molto elevati: dato che la finestra viene incrementata di un valore costante ad ogni RTT, le reti come quelle satellitari sono molto svantaggiate (si parla di RTT unfairness).
Nel corso degli anni sono state introdotte diverse varianti di TCP per mitigare questi problemi, fino ad arrivare alla situazione attuale in cui tutti i principali sistemi operativi utilizzano CUBIC come algoritmo di controllo della congestione predefinito.
A grandi linee CUBIC risolve i problemi di NewReno in due modi:
la crescita della finestra diventa indipendente dall’RTT non soffrendo quindi del problema della crescita troppo lenta su determinate reti;
la riduzione della finestra in caso di packet loss è meno drastica rispetto a NewReno e la fase di recovery utilizza una funziona cubica, molto più rapida nel tornare a regime. CUBIC prevede anche una fase di probing (che segue appunto la funzione cubica) per andare a scoprire se è disponibile ulteriore banda utilizzabile.
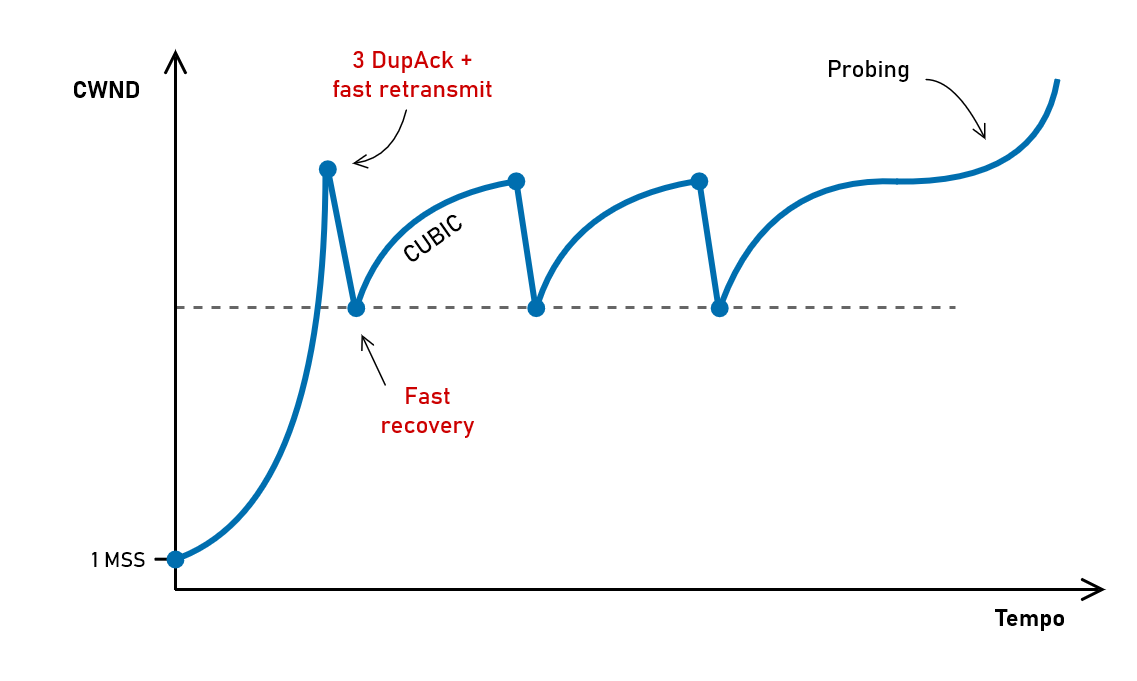
Il fatto che CUBIC sia superiore a NewReno diventa evidente con un esempio: se prendiamo un collegamento da 10 Gbps con RTT di 100 ms, per mantenere la velocità massima NewReno impone che non ci sia più di un pacchetto perso ogni ora, mentre per CUBIC appena 40 secondi.3
BBR
Come abbiamo visto, gli algoritmi di controllo della congestione “classici” si basano sul packet loss come segnale di congestione. Vanno quindi ad allargare la finestra di trasmissione fino al punto di saturare il collegamento. Un problema di questo approccio è che la presenza di buffer più o meno grandi nei router intermedi dà l’impressione che si possa trasmettere più dati di quelli realmente trasferibili, introducendo in realtà della latenza per via dei pacchetti presenti nelle code sui router.
Esiste a livello teorico la possibilità di calcolare la banda effettivamente disponibile sul collegamento di rete escludendo il ruolo dei buffer. In particolare possiamo calcolare la banda come il rapporto tra la finestra di trasmissione ideale e la latenza quando i buffer sono vuoti (quantità di dati massima per unità di tempo).
$$\operatorname{Bandwidth} = \frac{\operatorname{IdealWindow}}{\operatorname{Delay}}$$Se invertiamo la formula otteniamo che la finestra ideale che la connessione TCP dovrebbe avere è:
$$\operatorname{IdealWindow} = \operatorname{Bandwidth} \cdot \operatorname{Delay}$$Questa equazione è di fondamentale importanza e si chiama bandwidth-delay product (BDP). Se la finestra è inferiore al bandwidth-delay product significa che stiamo sprecando capacità di rete, mentre se è superiore stiamo andando oltre quello che la rete è in grado di offrire iniziando a riempire i buffer dei router.
La versione iniziale di BBR (Bottleneck Bandwidth and Round-trip propagation time), algoritmo ideato da Google nel 2016, si basa proprio su questo concetto, provando ad operare attorno al punto corrispondente al bandwidth-delay product nel tentativo di evitare di stressare i buffer e causare perdite di pacchetti.4
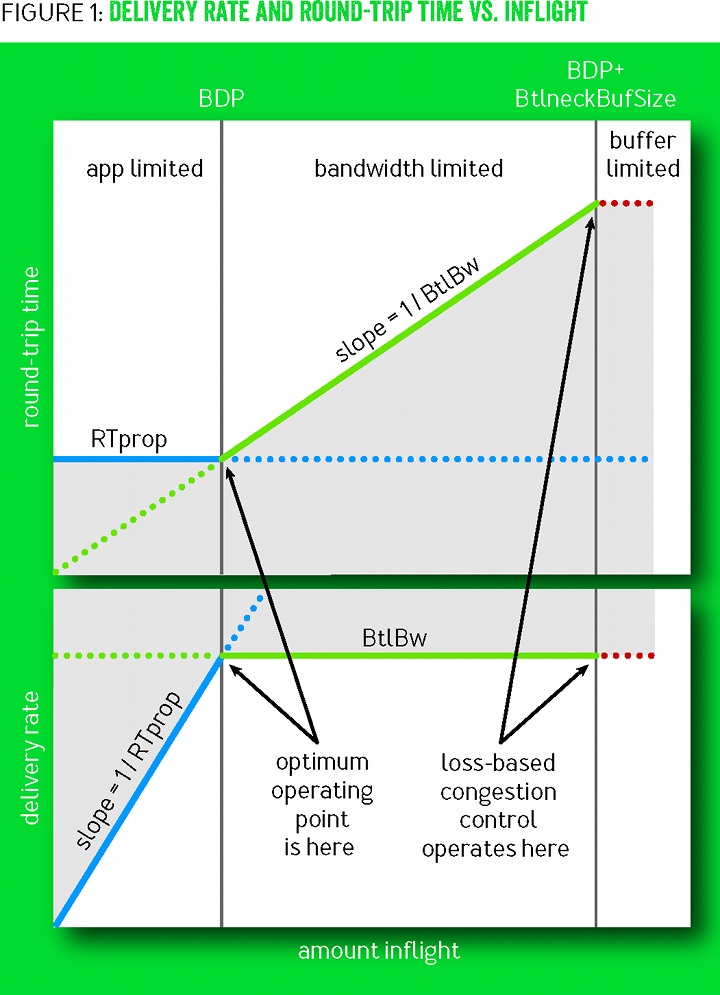
Nei grafici le due linee verticali si riferiscono rispettivamente al bandwidth-delay product e al collo di bottiglia della rete, più alto perché include l’effetto dei buffer dei router. Andando da sinistra verso destra stiamo aumentando la dimensione della finestra e quindi la quantità di dati trasmessi ma non confermati. Se stiamo “a sinistra” del bandwidth-delay product (prima linea verticale), vediamo che la velocità cresce regolarmente (grafico in basso) mentre la latenza resta stabile (grafico in alto), come ci aspetteremmo.
Una volta superato il bandwidth-delay product, che corrisponde alla banda massima della rete, la velocità non cresce più e aumenta invece il Round-Trip Time, perché i pacchetti iniziano ad essere messi in coda nei router creando ritardi nella consegna. Superata anche la seconda riga verticale (BDP+ o BtlneckBufSize), anche i buffer dei router sono pieni e inizia quindi ad esserci packet loss.
Mentre NewReno e CUBIC lavorano attorno al punto BDP+ (a destra), l’obiettivo di BBR è lavorare attorno al punto BDP (a sinistra), quello teoricamente ottimale.
Per poter calcolare il bandwidth-delay product BBR mantiene sia una stima della latenza di propagazione (l’RTT escludendo l’impatto dei buffer) sia della banda (calcolata solo se l’RTT non sta crescendo, altrimenti significa che saremmo già oltre il punto BDP). Il rate di trasmissione viene quindi regolato unicamente sulla base della stima del bandwidth-delay product.
In aggiunta, periodicamente BBR fa un probing della rete aumentando la finestra per vedere se è disponibile ulteriore banda. Anche in questo caso osserva se l’RTT aumenta per capire se sta andando oltre il punto BDP.
BBR ha nella pratica prestazioni di gran lunga superiori rispetto alle alternative come CUBIC, specialmente in situazioni in cui è presente già normalmente packet loss. Può inoltre essere abilitato anche soltanto da uno dei due host della connessione TCP, rendendo possibile un deployment solo lato server lasciando intoccati i dispositivi client.
I problemi di BBR e la nuova versione BBRv2
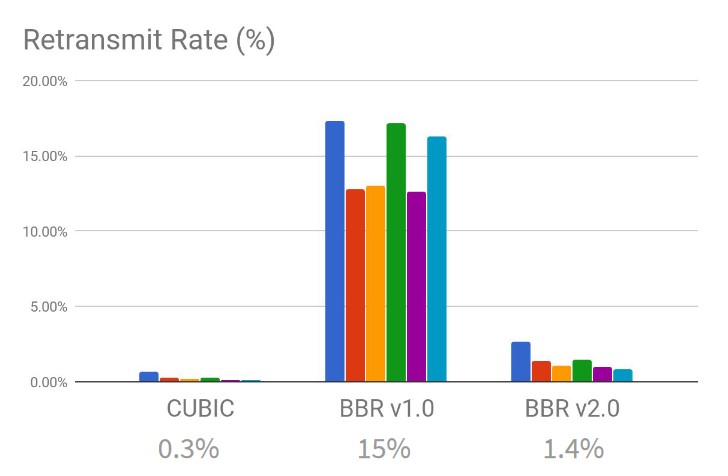
BBR non è perfetto e non riesce nella pratica a raggiungere pienamente l’obiettivo di non creare di proposito congestione sulla rete. Nelle situazioni in cui i buffer dei router sono piccoli (meno della metà del bandwidth-delay product) si hanno comunque perdite, che però BBR ignora per via di come è progettato.
Per questo motivo Google sta sviluppando BBRv2, ancora sperimentale, che tra le varie modifiche introduce un approccio ibrido che tiene in considerazione anche il packet loss come segnale esplicito di superamento della capacità della rete. Inoltre sfrutta anche Explicit Congestion Control se disponibile. Questo mix di approcci permette di ridurre drasticamente le ritrasmissioni causate da BBR pur mantenendo un throughput elevato.
Altre varianti
BBR non è la prima versione di TCP che prova a discostarsi dall’uso del packet loss come segnale di congestione. Ad esempio TCP Vegas (1995) utilizza l’aumento dell’RTT come segnale di congestione, con l’obiettivo di ridurre la velocità di trasmissione quando i buffer si stanno riempiendo.5
Un altro approccio è quello di TCP Westwood+ (2001), che quando rileva una perdita modifica la finestra di congestione in base a una stima del bandwidth-delay product. Westwood+ è stato sviluppato dal Politecnico di Torino e di Bari per poi essere implementato nel kernel di Linux, dove è tutt’ora disponibile come opzione.6
FAST TCP (2006) migliora Vegas con un metodo che ricalcola periodicamente la finestra di trasmissione in modo proporzionale rispetto a quanto l’RTT si discosta dall’RTT minimo, cioè idealmente la situazione in cui non c’è bufferbloat. Al tempo risultava essere una delle versioni di TCP con prestazioni migliori ma non ha mai preso piede.7
Compound TCP (2005) è una variante sviluppata da Microsoft (utilizzata per diversi anni su Windows Server prima di passare a CUBIC) che è sostanzialmente un mix tra NewReno e Vegas/FAST: tiene quindi conto sia delle perdite di pacchetti sia delle variazioni di latenza come segnali di congestione.8
Fonti
La maggior parte delle informazioni contenute in questo articolo sono presenti in qualsiasi libro introduttivo di reti, anche scolastico. Alcuni riferimenti utili sono i seguenti:
- Computer Networks (Andrew S. Tanenbaum)
- TCP/IP Illustrated, Volume 1 (Kevin R. Fall, W. Richard Stevens)
- Computer Networking: A Top-Down Approach (James Kurose, Keith Ross)
- An introduction to computer networks (Peter L. Dordal) [Creative Commons]
- Computer Networking: Principles, Protocols and Practice (Olivier Bonaventure) [Creative Commons]
Linux TCP_RTO_MIN, TCP_RTO_MAX and the tcp_retries2 sysctl, https://pracucci.com/linux-tcp-rto-min-max-and-tcp-retries2.html ↩︎
The NewReno Modification to TCP’s Fast Recovery Algorithm, RFC 2582 https://datatracker.ietf.org/doc/html/rfc2582 ↩︎
HighSpeed TCP for Large Congestion Windows https://datatracker.ietf.org/doc/html/rfc3649#section-1 ↩︎
BBR: Congestion-Based Congestion Control https://queue.acm.org/detail.cfm?id=3022184 ↩︎
Analysis and Comparison of TCP Reno and Vegas http://netlab.caltech.edu/FAST/references/Mo_comparisonwithTCPReno.pdf ↩︎
TCP Westwood+ congestion control https://c3lab.poliba.it/index.php/Westwood ↩︎
FAST TCP homepage http://netlab.caltech.edu/FAST/ ↩︎
Compound TCP https://wiki.geant.org/display/public/EK/Compound+TCP ↩︎